




Basics of Elasticsearch for Developer
Elasticsearch has been used more and more in the software engineering, data and DevOps fields. In this post I will write about the basics of elasticsearch from developer perspective.

So what is the definition of elasticsearch? according to elasticsearch’s website:
Elasticsearch is a distributed, open source search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. Elasticsearch is built on Apache Lucene and was first released in 2010 by Elasticsearch N.V. (now known as Elastic). Known for its simple REST APIs, distributed nature, speed, and scalability, Elasticsearch is the central component of the Elastic Stack, a set of open source tools for data ingestion, enrichment, storage, analysis, and visualization. Commonly referred to as the ELK Stack (after Elasticsearch, Logstash, and Kibana), the Elastic Stack now includes a rich collection of lightweight shipping agents known as Beats for sending data to Elasticsearch.
Writing to Elasticsearch
What happens if you insert a document to an index in elasticsearch? If you’re familiar with SQL and NoSQL databases, then you should know that there are many processes that happen when you insert a document into the database, one of reason of the processing is to optimize query speed. Same as other databases, there are also many processes that happen when you insert a document to elasticsearch, like determining field type, analyzing the text and in memory buffer system, but before that we need to know the most important thing when writing a data to elasticsearch, the Inverted Index
Inverted Index
Inverted index is the main thing that makes querying to elasticsearch blazingly fast. It is a data structure that maps term with its position in documents. For example when you are writing documents to elasticsearch like the following:
Document 1: “Elasticsearch is fast”
Document 2: “I want to learn elasticsearch”
Here is what it would like in the inverted index:
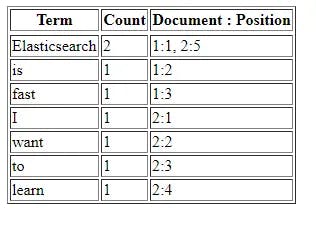
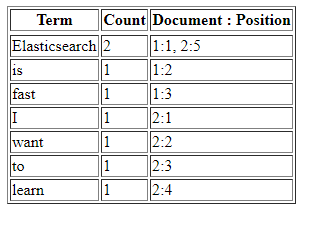
Now, every time you want to search “Elasticsearch” word then elasticsearch will looks into the term “Elasticsearch” in the inverted index and get the documents number from it.
Field Type
Just like another search engine or repository, elasticsearch has a field or mapping type which is used when writing a document to it. Like the other repositories, the field type in elasticsearch is very important in determining how will it be stored in inverted index, which relates to how are we able to get the data from elasticsearch.
You can insert mapping of field type by using elasticsearch’s mapping api, for example:
curl -X PUT "localhost:9200/my-index-000001?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
'</span>
If you don’t specify any mapping and insert a document to elasticsearch then by default elasticsearch will create the mapping for you. Please beware that it won’t be easy to change the mapping, so creating a mapping before inserting document to elasticsearch is recommended.
One thing to note if you’re beginner to elasticsearch is regarding the difference between text and keyword field type. The difference is actually quite simple, but will have a lot of impact when we do query. Text field will be analyzed(explained later) and keyword will not. Basically text won’t be inserted to the inverted index like exactly you type, for example by default, “Hello, World” will be inserted as “hello” and “world. So if you plan to do exact match query with your field, keyword field type is recommended. One more thing that you should know: if you didn’t specify any mapping, then elasticsearch will map String type to both text type and keyword type which can be accessed by “field” and “field.keyword”
If you want to learn more about the difference between text and keyword, you can read my other article
[## Elasticsearch: Text vs. Keyword
The differences between them and how they behave
medium.com](/better-programming/elasticsearch-text-vs-keyword-2ccb99ec72ae)
In Memory Buffer
A single shard can consist of multiple segments and memory buffer. When a Document is inserted to elasticsearch, it will first go into memory buffer before becoming a segment in a process called “refresh”. The refresh process is working in a configurable interval with 1 second as its default. The documents that are not in the segment won’t be able to be searched. This refresh process means that elasticsearch is not real time search engine since inserted documents need to wait for refresh process.
Analyzer
Analyzer consist of series of processes that happen to sentences to documents before it got inserted to inverted index. The processes are consist of: Character Filters, Tokenizer, and Token Filter.
Character Filters is the first process that happen in analyzer. It can be used for removing or replacing characters. For example, you can use Character Filter to filter out html tag, so things like , , , etc will be trimmed from the sentences
Tokenizer is a process of separating sentences into words. For example if you index the sentence “Elasticsearch is fast”, then the tokenizer will split the sentence into “Elasticsearch”, “is”, and “fast”. Elasticsearch has many type of tokenizer, but the most common used is its default tokenizer, which is based on http://unicode.org/reports/tr29/.
Token Filter is a process of transforming the words that came out from tokenizer, for exampling making the words lowercase.
Reading from Elasticsearch
Query
There are many queries that you can do in elasticsearch, in this post I will explain some that I believe is important to know to people that is learning about elasticsearch for the first time. which are:
- Match All Query: this query will get all of the documents in the index
curl -X POST \
'localhost:9200/index/_search' \
-H 'Content-Type: application/json; charset=utf-8' \
-d '{
"query":{
"match_all":{}
}
}'</span>
- Match Query: if you use Match Query, then your query will be analyzed before it get used to search the index. For example if you search “Hello, World” with Match Query, then your query will be become “hello” and “world” by default, note that if you have “Hello, World” in the inverted index it won’t be returned by elasticsearch, because your query is split.
curl -X POST \
'localhost:9200/index/_search' \
-H 'Content-Type: application/json; charset=utf-8' \
-d '{
"query":{
"match":{
"field": {
"query": "Hello, world"
}
}
}
}'</span>
- Term Query: similar with Match Query, but this time your query will not be analyzed. In previous example, if you’re search the index using Match Query with “Hello, World” as query and you have “Hello, World” document in the index then the document won’t be returned by elasticsearch, but with Term Query, it will be returned because the query is searched as it is.
curl -X POST \
'localhost:9200/index/_search' \
-H 'Content-Type: application/json; charset=utf-8' \
-d '{
"query":{
"term":{
"field": {
"query": "Hello, world"
}
}
}
}'</span>
- Bool query: If you want to combine queries, then you can use this one, there are 4 types of boolean query: Must, should, must_not and filter.
curl -X POST \
'localhost:9200/index/_search' \
-H 'Content-Type: application/json; charset=utf-8' \
-d '{
"query": {
"bool": {
"must": [
{
"match": {
"field": {
"query": "Hello, world"
}
}
},
{
"term": {
"field": {
"query": "Hello, world"
}
}
}
]
}
}
}'</span>
Aggregations
Elasticsearch has a powerful aggregation function compared to other databases. The simplest form of aggregation that elasticsearch can do is to bucket(group) documents, you might think that other databases can do bucketing with simple query too, but what’s so great about elasticsearch aggregation is that you can create a nested aggregation.
For example, this is one of the simplest aggregation in elasticsearch, range aggregation:
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 100.0 },
{ "from": 100.0, "to": 200.0 },
{ "from": 200.0 }
]
}
}
}
}
'</span>
will produces
{
...
"aggregations": {
"price_ranges": {
"buckets": [
{
"key": "*-100.0",
"to": 100.0,
"doc_count": 2
},
{
"key": "100.0-200.0",
"from": 100.0,
"to": 200.0,
"doc_count": 2
},
{
"key": "200.0-*",
"from": 200.0,
"doc_count": 3
}
]
}
}
}</span>
There are many more aggregations that elasticsearch can do, which you can read in their documentation.
Those are all things that I think you should know if you’re just started learning elasticsearch. I plan to write about the practical use and the high-availability about elasticsearch in another post. so, see you there :)